夏天的新片,一触即发。
3月10日之前,确定素材/剧本。
3月24日之前,确定演员。
3月24日,第一次剧组会议。
5月12日之前,拍摄前期准备,剧本、设备、道具就位。
5月12日,开始拍摄。
6月30日,最后一次拍摄,开始后期剪辑。
8月18日,剪辑完成,开始后期合成、制作字幕。
9月1日,发布,庆祝蓝色蒲公英一周年。
夏天的新片,一触即发。
3月10日之前,确定素材/剧本。
3月24日之前,确定演员。
3月24日,第一次剧组会议。
5月12日之前,拍摄前期准备,剧本、设备、道具就位。
5月12日,开始拍摄。
6月30日,最后一次拍摄,开始后期剪辑。
8月18日,剪辑完成,开始后期合成、制作字幕。
9月1日,发布,庆祝蓝色蒲公英一周年。
在SMC拍摄过程中,我也算是过了回导演瘾。
当时的感想就一个字——累。
每天到拍摄场地之后总不能闲着。
要给演员说戏,提醒他们背台词。
要布置场景,选择拍摄机位。
要组织大家工作,至少不能让他们闲着。
后来发现,台词我背得比演员都熟练。
SMC过后,静下心来仔细想了想,不足之处太多了。
首先是剧本,这个剧本没有意义啊,不知道要表现什么。
然后是导演,大多数地方都没有很好的体现剧本的意思。
后期也是个问题,有很多效果都没做出来。
还有演员的现场发挥,根本就没有现场发挥,太死板。
看过了《爱情呼叫转移》的拍摄过程花絮。
其中的亮点,就是演员的现场发挥。
其实有很多编剧遗漏的小细节,
如果演员发挥得好,就是对影片的锦上添花。
导演不是万能的,但是在场景设计上一定要全力以赴。
专业的导演事先会勾画出场景草图,这对于我们太难了。
但是,合理利用场景、灯光、道具,会给影片增色不少。
导演一定要参加后期剪辑,以保证故事是按照导演的思想进行的。
编剧是影片关键所在。
一部片是好是坏,主要取决于故事性,其次才是叙事手法。
镜头的灵活运用,属于画龙点睛之笔,可以让电影生动活泼。
有这么一种说法,在DV普及了之后,谁都可以拍片子了。
的确是这样,但是拍好拍坏就是另外一回事了。
SMC可以理解为一个失败的作品,但是却是一个里程碑。
SMC实现了从无到有,并且给我个人积攒了大量的经验。
总结了这么多,还都是停留在理论层面。
等着夏天,在新片中实践一下。
下了决心去做,就要做出我们的特点。
不能一味跟在别人屁股模仿。
模仿的再像,也只是别人的影子而已。
昨天漏了几个镜头没写,今天补上。
需要补加的镜头:
高岱送外卖
郭凡在Grocery Store买东西
Kelly在挑化妆品或者买衣服
片头一共1分30秒,背景音乐初步定下来选用Over the Hedge里面的《The Family Awake》。
三人出门,大概10秒
(以下三人路线穿插进行)
高岱路线:
上车
开车
高速公路(三秒慢镜头)
Rideau街
国会山
进校园
下车进楼
郭凡路线:
Rideau街公车站上7路车
7路车上跟拍
Bank Street街景
7路车进校园
下车进楼
Kelly路线:
进Rideau Center
上电梯
The Body Shop
Mexx
等公车
转小火车
下车进楼
穿插点:
1、郭凡上7路,7路车后跟高岱车,7路车开走街对面出现Kelly
2、Kelly进每一家店的时候穿插到其他两人
3、每一组镜头后面都是穿插点
其他拍摄要点:
1、三秒慢镜头要三脚架
2、Kelly在商场里用侧面跟拍
3、郭凡在公车上拍正面镜头
4、高岱车上在后座拍摄
5、可能需要补加在公交车下拍郭凡的镜头
暂时先想这么多。
前几天看了《爱情呼叫转移》,不可多得的新片啊。
顺便看了一下导演日志,获益匪浅。
原来当导演也有很多技巧,或者说,需要一个高速运转的头脑。
以前从不知道,导演还需要绘制场景草图。
以前也不知道,导演需要合理安排演员的档期与拍摄进度。
……
看来做导演真不是一件容易的事。光有热情是远远不够的。
夏天,我打算启动蓝色蒲公英第二部电影。
在有了第一部电影的经验,加上之后加盟的几位王牌成员,
估计第二部片会比第一部片在质量上有很大的飞跃。
前天拿下了Sony HDR-HC3,设备不成问题。
策划还要加上Rick。不过这家伙夏天要回国,运作还要我一个人。
剧本,最近还没有什么好主意。看看高岱那里有没有什么好素材。
导演,我想启用新人。目前还没有什么好的人选。
演员,等剧本出来再说吧。只要到时候有人不回国就行。
目前确定的项目成员:
策划:Rick、我
前期准备:高岱
拍摄协助:高莹莹
[caption id="attachment_69" align="alignnone" width="232"] 异步SRAM编码[/caption]
异步SRAM编码[/caption]
[caption id="attachment_70" align="alignnone" width="232"]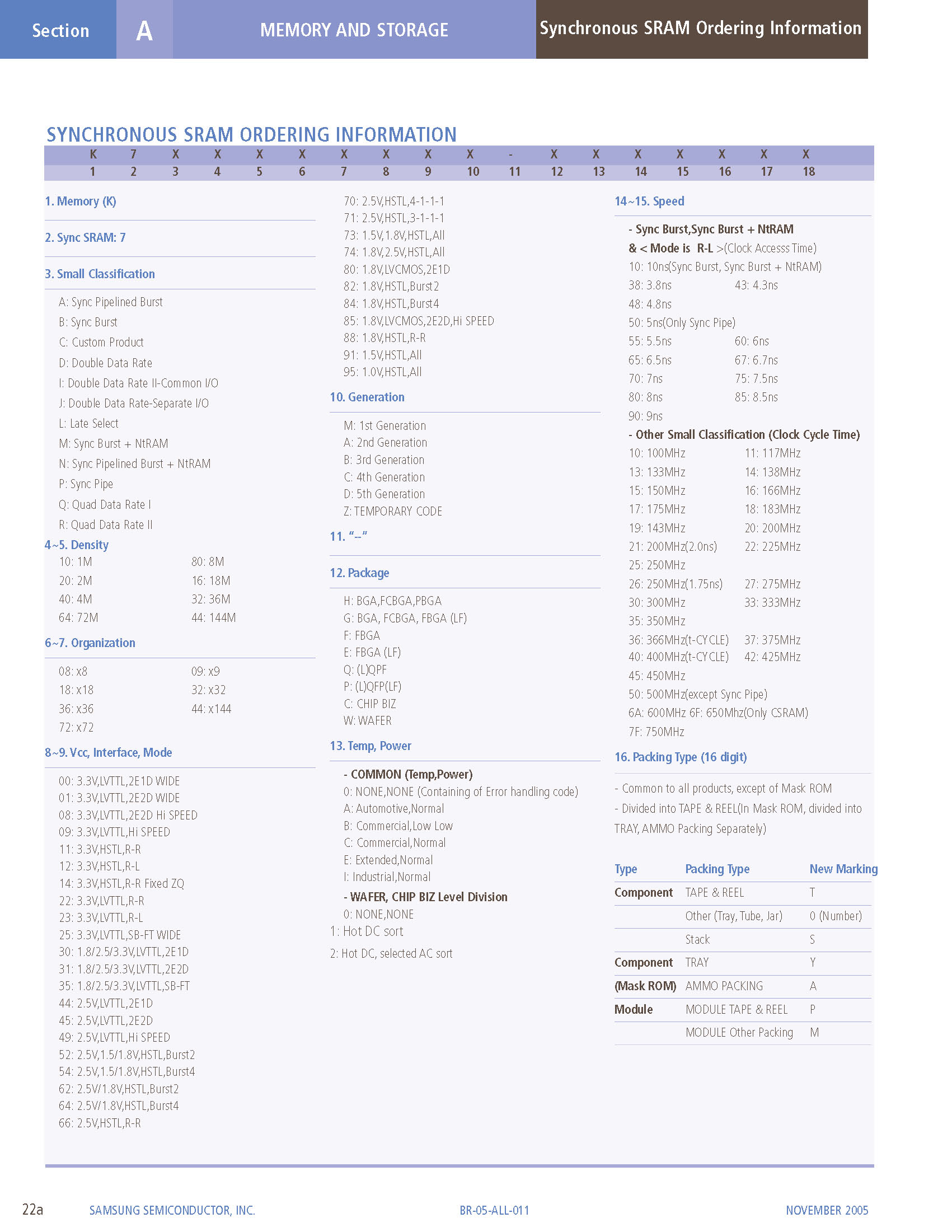 同步SRAM编码[/caption]
同步SRAM编码[/caption]
[caption id="attachment_68" align="alignnone" width="232"] NAND闪存编码[/caption]
NAND闪存编码[/caption]
[caption id="attachment_65" align="alignnone" width="232"]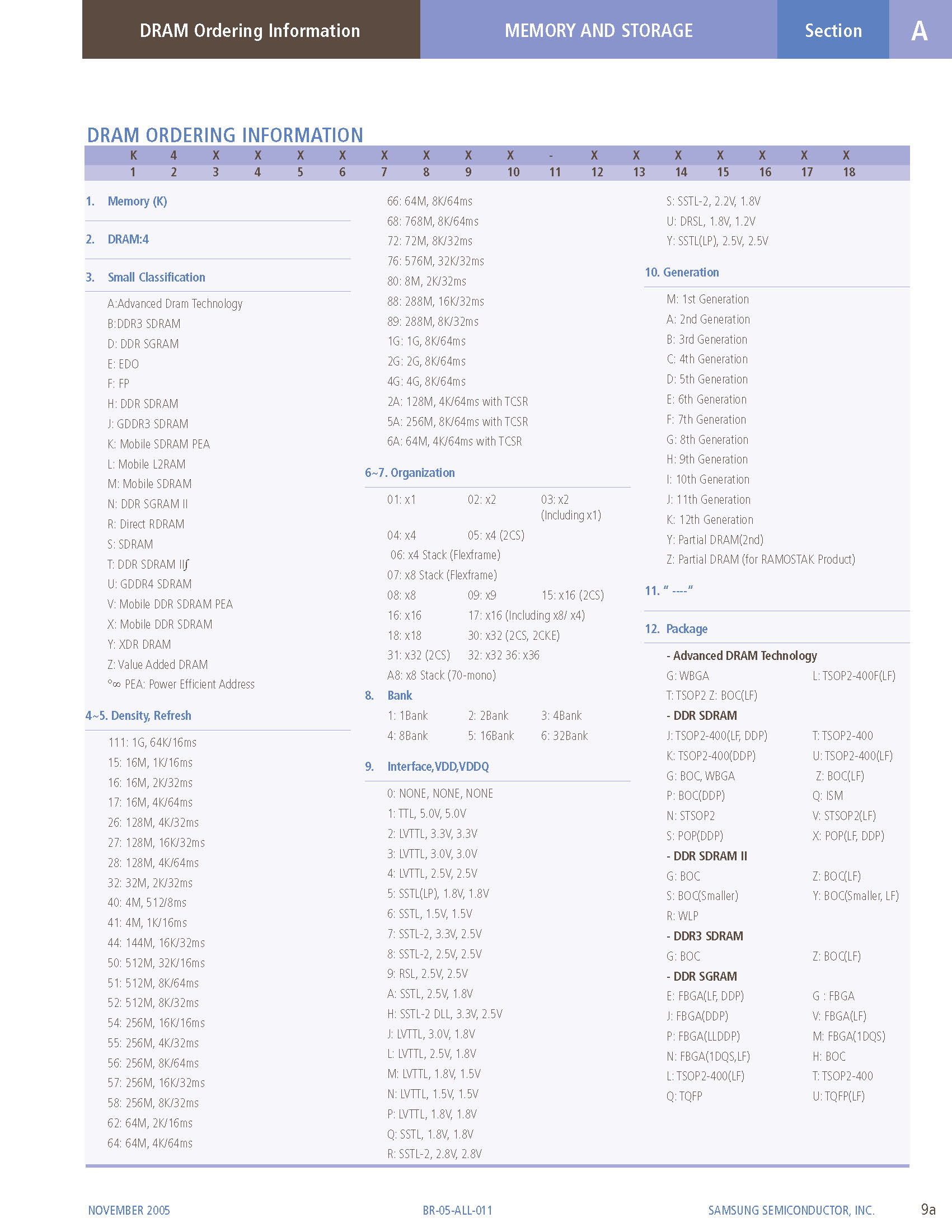 DRAM编码[/caption]
DRAM编码[/caption]
[caption id="attachment_66" align="alignnone" width="232"] DRAM编码[/caption]
DRAM编码[/caption]
[caption id="attachment_67" align="alignnone" width="232"]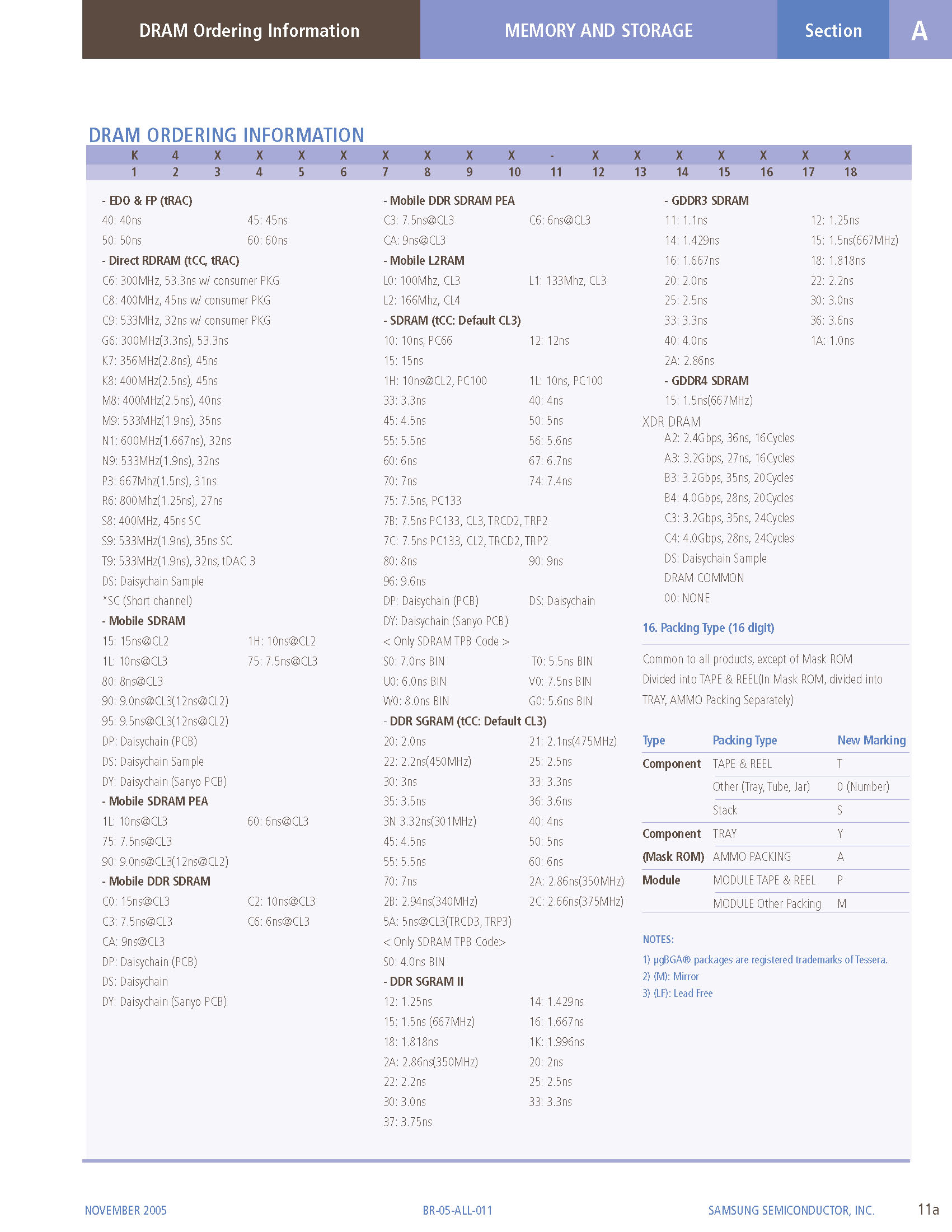 DRAM编码[/caption]
DRAM编码[/caption]
相对于1.0版本,Windows 2.0先进了许多。首先便是Windows 2.0使用了真正的图形界面,将原来的窗口只能平铺(tiled)改进为窗口可以互相重叠(overlapped)。另外,Windows 2.0支持80286以上的保护模式(Protected Mode),可以访问640KB以外的高端内存(DOS只能访问640KB低端内存)。而Windows/386则可以使用80386的虚拟8086模式(Virtual 8086 Mode, VM86)产生多个DOS虚拟环境。看来Windows与Intel的紧密结合早在10年前就开始了。
先介绍一下我的DELL小本的基本状况:
型号:Latitude C640
出厂时间:2002年12月3日
CPU:Pentium 4-M 2.4GHz(P4M的终结版,比较少见的处理器)
内存:出厂配置128MB x 2 = 256MB,后来自己换成512MB x 1
显卡:ATi Radeon 7500 Mobility(M7,也算经典的一款)
硬盘:出厂配置40GB,去年11月份出现坏道,质保更换为60GB
可爱的DELL小本跟了我3年半了。其间经历了很多曲折。在上一块硬盘报废之后,小本就一直睡在我的桌子上。只有当我想躺在床上看电影的时候才施展一下它的才华。
前几天躺在床上看电影的时候,突然发现硬盘异常。动用chkdsk详细检查,发现又出现了16KB的坏扇区。三年质保已经过了,想换硬盘也不可能了,唯一的方法就是关掉已经损坏的磁盘空间。拿出效率源检测,坏道出现在8%处。动用Partition Magic将坏道独立了出来。猛然间想到,怎么没看到诊断分区?
这个硬盘是在上一块硬盘报废之后通过质保更换的。看来DELL在更换硬盘的时候并没有把诊断分区设置好。自己动手,丰衣足食吧。
在网上搜索了一些关于诊断分区的文章(还真有好事者去研究这个诊断分区),发现诊断分区有独到的好处:
1、不受分区表限制,即便没有标注为活动(active),仍然可以在启动时按F12键选择启动
2、DELL的诊断工具是基于DOS操作系统的,也就是说可以安装任意的DOS系统在诊断分区,可塑性非常强
3、因为诊断分区设置为隐藏,并且标记为DE(下面会讲到),所以对系统没有任何影响
4、可以将Ghost放入诊断分区,实现系统快速恢复
好处这么多,看着都流口水,废话少说,拿出尘封已久的DOS知识开工吧!
这里要先提一下DOS操作系统。10年前,在Windows 95还没开发出来之前,没有人不知道DOS是什么东西。那个时候,人们盯着电脑,黑底白字,想着下一个命令语句,那感觉就像现在用Linux。但是,简单的DOS确成就了一批精品软件,PC-Tools、HD-COPY、UCDOS、WPS、CCED等等都是DOS时代的必备软件。后来出现了Ghost和Partition Magic,使得系统维护变得非常简便。现在,我终于要返朴归真,回到浪费脑细胞的DOS时代。
在网上找了一下DOS软件下载,还真不少。总结一下,大体上需要以下软件:(有具体需求的话可以自行添加)
1、MS-DOS 7.10,目前为止最稳定功能最强大的操作系统,可以识别长文件名和大容量硬盘
2、DELL Diagnostics Tools,DELL的诊断工具,可以从官方网站上下载
3、Partition Magic for DOS,DOS下的分区管理工具,可以在不损伤数据的前提下自由调整分区大小
4、Ghost for DOS,系统恢复易如反掌
同时我们还需要另外几个工具软件来创建诊断分区:
1、Partition Magic,之前已经介绍过了,这里我们只需要Windows部分
2、PTedit,分区表修改工具,Partition Magic的一个附件
软件下载回来之后,动手开工:
1、创建诊断分区(若已存在诊断分区则跳过这一步):使用Partition Magic划出一个30-100MB的分区,格式化为FAT16格式。
2、如需要恢复分区,可以再分出5-8GB,格式化成FAT32或者NTFS
(由于我的小本60GB硬盘在8%处出现坏道,所以我给分成100MB + 6GB + 15GB + 30GB,大概损失1GB作为坏道隔离区)
2、使用PTedit将启动分区设置为诊断分区(将Boot Record设置为80,同时将现有的启动分区的Boot Record设置成00)
软件下载:
新DOS时代:http://www.cn-dos.net/newdos/dosmain.htm
参考资料:
Inside the Dell Utility Partition:http://www.goodells.net/dellutility/
DOS扩展工具介绍:http://www.cn-dos.net/msdos71/readmecn.txt
在上一节,讲了关于如何处理120fps片源的问题。还记得最后是怎么做的吗?和Timecodes一起,把压制出来的东西封装成MKV。这里MKV是作为真正支持VFR的媒体容器使用。这样的话,片源也就可能使用MKV封装,里面混合着24fps和30fps(甚至还有60fps)的片段。AVS是不支持VFR(注:VFR就是指可变帧速率,播放的时候fps可以改变),如果还像原来那样内嵌,那么时间轴就会有困难。因为如果全部AssumeFPS(还记得这个AVS语句么?)成24或30,都会导致时间轴变得不准,那么怎么办呢?方法还是有的,上一节的片源是用D帧来占时间,那么我们人为地造出D帧来用于内嵌,内嵌好以后再把这些多出来的帧删除,问题就解决了。
本节新用到的AVS语句:
Directshowsource("文件名",fps=帧速率) 使用类似Windows自带的媒体播放器打开文件的方式调用片源,效率远远低于AviSource。不到万不得已请不要使用。
Selectevery(n,n1,n2,n3……) 这个是Selectevery的一个新语法,意思是以n为周期,取每一个周期里的第n1 n2 n3……帧。这可能不太好理解,举例:
片源的帧是123456789,执行了selectevery(4,1,4)就会变成1458。如果用了selectevery(1,1,1,1,1)就会变成111122223333444455556666777788889999(就是这个,变成120fps的方法)。
1 、片源的加载
因为这次的片源是MKV,就不能像原来那样加载了。当然,把MKV里面的AVI(如果封装的时候加入的是AVI)解出来处理是可以的,效率很高。如果解出来是其他什么格式(比如x264压制出来的MP4被封装在里面),可以考虑使用AVS的Directshowsource语句。
DirectshowSource语句是加载视频的语句,与AVISource不同的是,Directshowsource使用Directshow方式加载视频(也就是WindowsMediaPlayer使用的那种加载方式)。使用Directshowsource语句加载视频最好要指定fps,比如fps=29.97。事实上,WindowsMediaPlayer配合各种Splitter(就是把封装格式解来播放用的,比如Windows自带AVISplitter)可以播放各种格式,甚至RMVB也可以。
使用方法也是很简单,就像这样:directshowsource("c:\1.mp4",fps=29.97)
2 、VFR的还原
上一节介绍的封装MKV法,在封装MKV的时候还一起进去了个Timecodes。现在我们要利用这个Timecodes在AVS里把片源处理成120fps的,然后就和处理120fpsAVI片源一样的方法处理就可以了。
首先要把这个Timecodes解出来。我考虑到很多人可能到现在还不会使用命令行,所以就写了一个小工具SMEG,专门用来解MKV(功能很弱,各位高手不要见笑)。把这个工具放在当时安装MKVToolnix的地方,然后运行即可。界面是中文的,我想我也不用多说什么,把里面的Timecodes解出来即可。
利用已经讲过的语句,就可以把没有D帧的片源处理成120fps的了。首先用Trim取一段,然后用Selectevery把这一段处理成120fps,然后Assumefps到120。这个如果手工来的话也是有很大工作量,所以我也写了一个程序自动生成AVS。同样用Import命令即可。加载时片源的fps可以随意指定,在这一步片源的fps就失效了。
例:生成的AVS像这样:
[code]
b0=trim(0,40).selectevery(1,1,1,1,1,1).assumefps(119.88)
b1=trim(41,122).selectevery(1,1,1,1,1).assumefps(119.88)
b2=trim(123,412).selectevery(1,1,1,1,1,1).assumefps(119.88)
b3=trim(413,2624).selectevery(1,1,1,1,1).assumefps(119.88)
b4=trim(2625,2836).selectevery(1,1,1,1,1,1).assumefps(119.88)
b5=trim(2837,2926).selectevery(1,1,1,1,1).assumefps(119.88)
b6=trim(2927,3600).selectevery(1,1,1,1,1,1).assumefps(119.88)
b7=trim(3601,3840).selectevery(1,1,1,1,1).assumefps(119.88)
b8=trim(3841,8435).selectevery(1,1,1,1,1,1).assumefps(119.88)
b9=trim(8436,8547).selectevery(1,1,1,1,1).assumefps(119.88)
b10=trim(8548,13954).selectevery(1,1,1,1,1,1).assumefps(119.88)
b11=trim(13955,14034).selectevery(1,1,1,1,1).assumefps(119.88)
b12=trim(14035,14884).selectevery(1,1,1,1,1,1).assumefps(119.88)
b13=trim(14885,14950).selectevery(1,1,1,1,1).assumefps(119.88)
b14=trim(14951,15401).selectevery(1,1,1,1,1,1).assumefps(119.88)
b15=trim(15402,15781).selectevery(1,1,1,1,1).assumefps(119.88)
b16=trim(15782,17480).selectevery(1,1,1,1,1,1).assumefps(119.88)
b17=trim(17481,17720).selectevery(1,1,1,1,1).assumefps(119.88)
b18=trim(17721,32489).selectevery(1,1,1,1,1,1).assumefps(119.88)
b19=trim(32490,34286).selectevery(1,1,1,1,1).assumefps(119.88)
b20=trim(34287,34558).selectevery(1,1,1,1,1,1).assumefps(119.88)
b21=trim(34559,34632).selectevery(1,1,1,1,1).assumefps(119.88)
b22=trim(34633,35013).selectevery(1,1,1,1,1,1).assumefps(119.88)
b0+b1+b2+b3+b4+b5+b6+b7+b8+b9+b10+b11+b12+b13+b14+b15+b16+b17+b18+b19+b20+b21+b22
[/code]
3 、挂字幕
之前已经说了好多遍了,不重复了。
4 、去D帧
和处理120fpsAVI的片源没有两样,通过Timecodes生成一个AVS然后Import。
5 、压制
这个是你自己的事了……
6 、封装
和Timecodes一起,封装进MKV。
7 、附录:如何拆MKV
AVI的音频可以使用VDM来解,那么MKV里面的音频呢?
为了解决这些问题,本节多了这个附录……
首先是分析MKV里面哪一个流是什么。安装MKVToolnix以后,会有一个mkvinfo GUI在开始菜单里。这个是用来查看MKV信息的。运行这个,会弹出一个窗口,点击File->Open,选择你要拆封的MKV文件,打开以后,MKV的信息就显示出来:
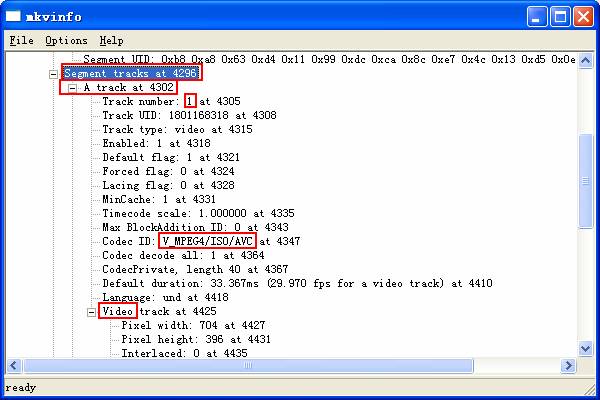
信息很多,而且比较杂。只要从里面找出关键信息,其他可以不要管他。
首先是“Segment tracks at 4296”,数字可能有所不同。意思是这里开始是轨道信息。
然后是“A track at 4302”,数字可能有所不同,意思是这里开始是一个轨道。
轨道号在这里,一定要记住。这个“Track number:1 at 4305”,1是轨道号。
编码决定了这个轨道是否可以解出来和解出来用的扩展名。找到“Codec ID”。这里显示的是“V_MPEG_4/ISO/AVC”。如果你看到的也是这个,就说明要解成.264文件,封装成MP4,用Directshowsource加载。最开始的“V_”表示这个是视频,如果是“A_”就说明这个是音频。
找好你要解的轨道以后,运行SMEG,在“拆指定流”后面输入轨道号,然后点击“拆”,会叫你保存拆出来的文件。这里输入文件名以后,还要输入扩展名。扩展名很重要,决定扩展名要根据“Codec ID”,如果是XVID等等之类的就是AVI,文件名就像这样输入:"c:\1.avi"。如果是MPEG-1 Layer3就是MP3,AAC就是AAC……凭经验吧,不会了还可以把Codec ID贴出来,拿到论坛问。
附录2:.264文件封装成MP4的方法
搜索,然后下载MP4Creator。使用方法也很简单,还是怕有人不会,写了GUI……放在一起,运行,选择.264文件,OK……
在内嵌的时候,经常会遇到一些很奇怪的片源。这些片源大小和普通片源看起来没什么差别,可是压缩的时候几个小时都完不成,好不容易等死等活地等完了,发现播放的时候不是卡卡的就是CPU吃了100%甚至就来“发送错误报告”了。究其原因,在打开片源的时候多留一个心眼儿,发现这个片源的FPS有点诡异(注:FPS指的是帧速率,就是每秒钟显示几张图)。
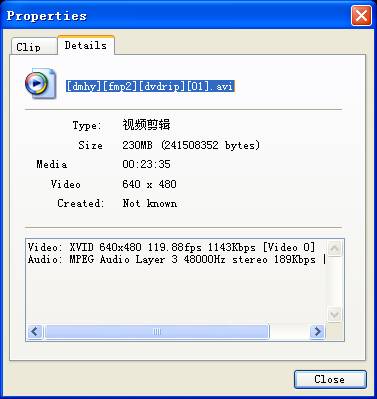
看到了吗?这个FPS是119.88,也就是所谓的120fps了。事实上,这个视频文件不是真的每秒钟播放120张图,也是和普通的片源一样每秒钟播放24或30张图。不同之处在于这个AVI文件里面有一种帧,叫做“D帧”。作用是占时间,播放的时候会被忽略。这样说可能还是不好理解,还是还是排列出来就一目了然了:用K表示普通帧,D表示D帧:
24fps的:K K K K K K
120fps的:KDDDDKDDDDKDDDDKDDDDKDDDDKDDDD
会发现都是一样的。24fps的有6帧,播放需要0.25秒。而120fps的有30帧,播放也是0.25秒。而实际上,120fps那里只有6帧是K,也就是说两个都是一样的。
那这样用24不就好了,为什么要弄一个120出来呢?是因为,还有一种常见的帧速率是30fps。当动画片种既出现30fps又出现24fps,AVI是不能一个文件拥有多种fps的。那么,就用120fps,既可以包含30fps的部分,又可以包含24fps的部分。
在压制的时候,我们压制的都是K帧,如果你就这样把120fps的东西送去压制,出来的结果就是全部的D都变成K,这样怎么行?不仅播放的时候暴耗CPU,浪费压制的时间,还无意义地增大了文件地体积。在压制之前,要先把D帧去掉。
本节新出现的AVS语句:
selectevery(n) 每n帧取一帧。比如原来是123456789,那么用了selectevery(3)以后就会变成147。
import("文件名") 导入另一个AVS文件,效果和把这个AVS文件的代码粘贴进来一样。
assumefps(目标帧速率) 更改帧速率,不改变帧数(改变时间)。比如原来有30帧,fps由30改为24后,播放时间变为1.25秒。
原理很简单,在30fps的片段用selectevery(4),在24fps的片段用selectevery(5)。那么如何判断哪些地方是24fps,那些地方是30fps呢?从AVI中可以导出一个文件叫做timecodes,这个文件里面记录了每一个K帧出现的时间。通过这个文件,我们可以判断出哪里是帧交替点。这里介绍一个我写的自动判断的工具,把timecodes送进去它会出来一个AVS文件,里面就是刚才介绍的selectevery()语句之类的东西。在对片源加载好字幕以后,导入这个AVS即可去除所有D帧,接下来就是送去压制。
例:这个是片源AVS:
[code]
loadplugin("c:\program files\avisynth 2.5\plugins\vsfilter.dll")
avisource("[dmhy][fmp2][dvdrip][01].avi")
textsub("[dmhy][fmp2][dvdrip][01].ssa")
import("[dmhy][fmp2][dvdrip][01].deldf.avs")
[/code]
这是[dmhy][fmp2][dvdrip][01].deldf.avs
[code]
a0=trim(0,206).selectevery(5).assumefps(29.97)
a1=trim(209,535).selectevery(4).assumefps(29.97)
a2=trim(538,1983).selectevery(5).assumefps(29.97)
a3=trim(1987,10833).selectevery(4).assumefps(29.97)
a4=trim(10836,11891).selectevery(5).assumefps(29.97)
a5=trim(11895,12253).selectevery(4).assumefps(29.97)
a6=trim(12256,15622).selectevery(5).assumefps(29.97)
a7=trim(15625,16584).selectevery(4).assumefps(29.97)
a8=trim(16586,39557).selectevery(5).assumefps(29.97)
a9=trim(39560,40007).selectevery(4).assumefps(29.97)
a10=trim(40009,67039).selectevery(5).assumefps(29.97)
a11=trim(67043,67361).selectevery(4).assumefps(29.97)
a12=trim(67364,71610).selectevery(5).assumefps(29.97)
a13=trim(71613,71875).selectevery(4).assumefps(29.97)
a14=trim(71878,74128).selectevery(5).assumefps(29.97)
a15=trim(74132,75650).selectevery(4).assumefps(29.97)
a16=trim(75653,84143).selectevery(5).assumefps(29.97)
a17=trim(84147,85105).selectevery(4).assumefps(29.97)
a18=trim(85108,158948).selectevery(5).assumefps(29.97)
a19=trim(158952,166138).selectevery(4).assumefps(29.97)
a20=trim(166141,167496).selectevery(5).assumefps(29.97)
a21=trim(167500,167795).selectevery(4).assumefps(29.97)
a22=trim(167797,169696).selectevery(5).assumefps(29.97)
a0+a1+a2+a3+a4+a5+a6+a7+a8+a9+a10+a11+a12+a13+a14+a15+a16+a17+a18+a19+a20+a21+a22
[/code]
虽然这个看起来复杂,但是是没有奇怪的语句,而且是程序自动生成,不用自己写。
为什么要先挂字幕,而不先去除D帧呢?因为D帧是用来提供24fps和30fps混合的,去掉D帧fps会混乱,字幕的时间就不准了。
这里介绍一下这个删除D帧的AVS的取得办法:
首先用附带的工具取得timecodes。方法是把AVI文件拖动到avi2timecode的图标上,一个TXT就会出来。然后把这个TXT拖到120tcv2toavs图标上,这个AVS就会出来了。
最后压制完时间还是不准的,要进行处理。这里推荐封装成MKV格式。压制出来有一个视频文件,片源中解出来音频文件,然后和timecodes一块儿封装到MKV里面。
封装MKV用的是MKVToolnix,封装方法:
首先启动mkvmerge GUI(这个软件启动比较慢,耐心点),然后加载压制成品和音频,在轨道那里选中视频:
![]()
下方找到这个:
![]()
把一开始用avi2timecode生成的那个TXT文件弄到这里,然后和平时一样照常封装即可。
附:封装MKV的方法
MKV类似于AVI,是一种封装格式,说白了就是给音频流和视频流提供放的地方。MKV要比AVI先进,比如AVI的120fps是为了使24fps和30fps的得以混合,而MKV自身就是可以支持24fps和30fps混合的,不需要借助什么120fps。MKV还有很多比AVI先进的地方,大家还是慢慢体会吧。如果没有什么视频基础知识,要播放MKV我推荐使用MediaPlayerClassic,播放方法和播放普通的视频没什么区别。这里介绍一下MKV的制作方法。
制作MKV通常是借助一个叫做MKVToolnix的工具。首先下载下来安装,运行那个mkvmerge GUI就会出现如下窗口:
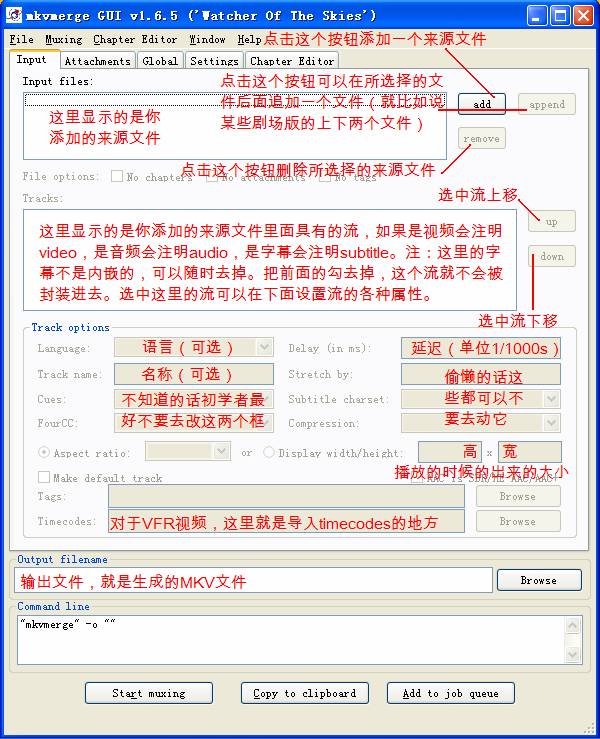
按照上面说的操作就可以了……
1 、初识AVS
首先必须明确,AVS是什么东西?
AVS的全称是AviSynth。还记得用VDM内嵌字幕的时候是怎么做的吗?先打开片源,然后挂字幕,最后送到编码器压制。所以说到最后,VDM的工作就是给编码器提供带有字幕的视频。AVS的功能也是差不多,就是输入源视频,输出处理过的视频。AVS的处理过程全部保存在AVS文件里。对于AVS文件,我们可以把它当作是视频文件,因为安装好AviSynth以后,AVS文件可以像AVI那样被VDM打开,甚至能被播放器打开。
AVS文件中包含的是处理信息。先举个简单的例子。比如之前的用VDM内嵌字幕,现在改用AVS内嵌字幕。VDM启动的时候自动加载字幕插件,先打开片源,然后添加字幕插件。用AVS的话就可以这样写:(文件名自己改)
[code]
loadplugin("c:\vsfilter.dll")
avisource("c:\1.avi")
textsub("c:\1.ssa")
[/code]
我来解释一下,第一句中的loadplugin()意思是加载插件,括号里面就是插件的名字。在VDM里面启动时会自动加载插件,AVS中要手动写这一句。vsfilter.dll是字幕插件的名字。然后是avisource(),这个是加载AVI的功能,就像VDM中的打开文件。textsub这个功能本来AVS没有,是加载完vsfilter.dll这个插件以后才有的。就像是VDM在没有加载字幕插件的情况下在Video->Filter里面不会出现textsub这个东西。textsub()括号里面的是字幕文件的名字。
以上内容用记事本写好,保存的时候在文件名后面加上“.avs”。然后这个AVS文件拿去用播放器打开试试,播放出来有字幕的影片了吗?
这样还只是出来一个AVS文件而已,字幕并没有真正跑到影片里面去。刚才看到的是AVS输出的画面,只要把这个画面拿去压制就可以出来有字幕的文件了。可以使用VDM进行压制。在VDM打开文件的时候,直接选择AVS文件,然后不要再挂字幕了,设置好以后送去压制就可以了。
2 、特效的内嵌
AVS强大的功能还不止这一点,现在再介绍复杂一点的AVS操作。比如特效,字幕组的人经常会把特效制作成AVI格式或者字幕格式。如果是字幕格式,那好办,用AVS就这样写:
[code]
loadplugin("c:\vsfilter.dll")
avisource("c:\1.avi")
textsub("c:\1.ssa")
textsub("c:\tx.aas")
[/code]
和刚才相比,就多了一句,再加载一次字幕而已。如果是AVI的特效,比如是片头,就是去掉原来动画片的片头,把这个AVI塞进去充当片头。就是说用AVI里面的内容替换片源的内容。先要找到片源中要替换的部分的位置。这个用VDM操作。用VDM打开片源,拖动下面的滚动条找到片源中要替换部分的开头,
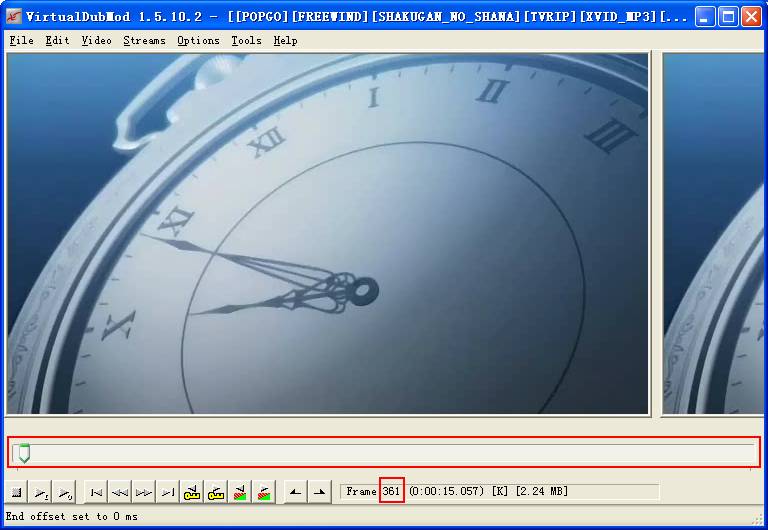
这里的开始位置就是361,记住这个数字。然后用同样的方法找到结束位置,这里找到的是2519。再把滚动条移动到最后面,找到总帧数,这里是35963。然后找出那个AVI特效。这里假设片源是c:\py.avi,字幕是c:\zm.ssa,特效是c:\tx.avi。
[code]
loadplugin("c:\vsfilter.dll")
py=avisource("c:\py.avi",audio=false).textsub("c:\zm.ssa")
tx=avisource("c:\tx.avi",audio=false)
py.trim(0,360)+tx+py.trim(2520,35963)
[/code]
这个AVS会相对比较复杂。解释一下:
[code]
loadplugin("c:\vsfilter.dll") #加载字幕插件
py=avisource("c:\py.avi",audio=false).textsub("c:\zm.ssa") #加载片源并挂字幕
tx=avisource("c:\tx.avi",audio=false) #加载特效
py.trim(0,360)+tx+py.trim(2520,35963) #用特效代替片源中的部分
[/code]
和前面相比,又多了一些东西。在加载片源语句中,多了一个audio=false,这个的意思是加载片源的时候不加载音频。以此类推,加载特效的时候也没有加载音频。音频的话可以在最后压制好再混合。这样就直接在AVS里面禁掉了音频,不用在VDM里面选audio->No audio了。加载语句的后面跟了一个点,然后是加载字幕。点的作用是分割,意思是加载好片源以后紧跟着挂字幕。为的是写在同一行。写在同一行的理由在这一行的开头,就是那个py=。它的意思是这一整行出来的结果用py表示。下面的也是,特效加载好以后用tx表示。接下来是最后一句。py.trim(0,360)的意思是在py中截取第0帧到第360帧。因为片源要替换的部份是从361帧开始的,我们不能把要替换的部分截出来,py.trim(2520,35963)的意思是把片源的2520帧到35963帧截出来。加号表示连接。连起来,最后一行就是先把输出py的0-360帧输出,然后输出tx,tx输出完了就把py的2520-35963输出。这样看起来,就是py中361-2519的那部分没掉了,取而代之的是tx。这样,特效就用进去了,然后送到VDM压制。
总结:这一次介绍的AVS内容归纳起来有以下几点:(中括号内表示可有可无)
[code]
loadplugin("插件文件的位置、文件名") #加载AVS的插件
avisource("文件名"[,audio=false]) #加载AVI文件,可以用audio=false禁止加载音频部分
trim(起始帧,终止帧) #截取片段
textsub("字幕文件名") #AVS插件VSFilter中的语句,加载字幕
[/code]
一、简述
AviSynth是AVI SYNTHesizer的缩写,意思就是AVI和成器,是一个Frameserver。(Frameserver就是一个把影像文件从一个程序转换到另外一个程序的过程,其间没有临时文件或中介文件产生)
AviSynth是由Ben Rudiak-Gould首创的一种非常有用的工具,能够提供各种方式来合并和滤镜处理影像文件。最独特的就是AviSynth并不是一个孤立的影像处理程序,而是在影像文件和应用程序之间担任“中间人”的角色。
AviSynth的基本工作原理是这样的:
首先建立一个包含特定命令的文本,称之为“脚本”(后缀为avs),这些命令指定要运行处理的影像文件和滤镜;
然后运行影像应用程序,比如VirtualDub或NanDub,打开脚本。此时AviSynth就开始工作了,打开脚本中指定的影像文件,运行特定的滤镜,并把输出结果提供给影像应用程序。但影像应用程序并不了解AviSynth在后台所做的处理,而认为是直接打开了一个“被处理过”的影像文件。
因此使用AviSynth有5大优势:
1. YUV支持:内建滤镜可以在YUV环境下运行,第三方滤镜几乎也兼容YUV,所以比起VirtualDub、NanDub的内嵌滤镜必须在RGB环境下运行要快很多。省却了一个转换的过程,将来还可以支持YV。
2. 滤镜处理:内建许多影像处理滤镜,比如Resizing,Cropping等。还有大量的第三方强力滤镜,并可以调用VirtualDub以及AviUtl的第三方滤镜。
3. 突破2G限制:通过AviSynth打开影像文件就相当于应用程序直接打开,这样就可以使本身有2G限制的程序也能突破2G的限制。
4. 打开格式:AviSynth可以打开几乎所有影像文件,包括MPEG和QuickTime。所以当影像应用程序通过AviSynth打开这些文件时,会被认为是打开标准的AVI,这样就可以处理影像应用程序本身并不支持的格式。
5. 节省硬盘空间:AviSynth处理的影像文件在运行过程中直接导入应用程序,没有临时文件,所以节省硬盘空间。
AviSynth现在有3个版本,第一个是Ben Rudiak-Gould的首先编译的AviSynth v1.0b;在Ben Rudiak-Gould停止开发后,Edwin van Eggelen继续开发,最新的版本是AviSynth v1.0b6;在2002年7月第二次源码编写计划开始,目前最新的版本是AviSynth v2.0.6,新的v2.5版还在开发中。
最后一个版本比较强大,更新速度快,增加了许多实用的命令,也吸收了一些优秀的第三方滤镜成为内建滤镜,强力推荐使用。
二、安装
AviSynth的安装可谓简单,先下载AviSynth,然后解压缩,把AviSynth.dll复制到Windows\System下(W98,ME)或Windows\System32下(W2K,XP),然后运行INSTALL.REG就完成安装了。
三、内建滤镜
AviSynth内建了数目繁多的滤镜,所以只能介绍一些最常见实用的一部分。
1、源文件滤镜
① AVISource
导入AVI,对于DivX或XviD,需要安装相应的Codec。
例:AVISource("test.avi")
② WAVSource
导入WAV
例:WAVSource("test.wav")
2、处理滤镜
① AddBorders
加边:给影像加黑边,尤其适用于对16:9的影像加字幕,希望不影响图像,把字幕加在图象的下方的情况。参数是整数,顺序是左、上、右、下。
例:AddBorders(0,64,0,64) # 把640*352(16:9)改成640*480(4:3)
② ConvertToRGB 和 ConvertToYUY2
改变颜色环境:
VirtualDub和AviUtl第三方滤镜有的需要RGB环境才能运行,需要ConvertToRGB来进行切换。
有的RAW文件是RGB的,但调用的AVISynth滤镜只能运行在YUV下,就需要用ConvertToYUY2来运行。
例:ConvertToRGB() # 改变成RGB颜色环境
ConvertToYUY2() # 改变成YUV颜色环境
③ Crop
切边:为了保持比例或切除黑边,参数是整数,顺序是左、上、宽、高。
例:Crop(8,0,704,480) # 左右各切去8,以保持比例
④ Levels
层次:调节亮度、对比度和Gamma值。
例:Levels(0,1.2,255,0,255) # 调整Gamma,使画面变亮
⑤ LanczosResize
放大缩小:Lanczos采样方法可以在图像处理中看到,是BicubicResize的替代者,提供更精准、更锐利的画质。本来是日本人开发的第三方滤镜,在日本普遍使用,欧美使用BicubicResize。自2.05版本开始吸收为内置滤镜。
例:LanczosResize(640,480) # 把分辨率改变为640x480
⑥ Tweak
调整:可以调节色度,饱和度,亮度,对比度。
色度:-180.0~180.0,默认0.0。正数趋向红色,负数趋向绿色。
饱和度:0.0~10.0,默认1.0。0.0为黑白。
亮度:-255.0~255.0,默认0.0。
对比度:0.0~10.0,默认1.0。
3、编辑滤镜
①FadeIn 和 FadeOut
淡入和淡出:提供淡入和淡出功能,尤其是淡出功能,可以使影片结束地更自然。参数为整数,表示需要编辑的帧数。
例:FadeOut(24) # 影片最后1秒淡出
②Trim
截取:决定需要处理的部分。参数为整数,表示需要编辑的开始帧和结束帧。对抽样做Sample比较有用。
例:Trim(240,480) # 决定处理240~480这一片断
4、声音滤镜
① AudioDub
影音合并:可以把影像和声音合并在一起。适用用用Helix直接做RMVB格式的DVDrip。
例:Video = AVISource("test.avi")
Audio= WAVSource("test.wav")
AudioDub(Video,Audio) # 把test.avi和test.wav合并
② GetLeftChannel 和 GetRightChannel
获取声道:把立体声的左右声道单独返回,适用于左右声道不同语种的WAV。
例:stereo=WavSource("test.wav")
return GetLeftChannel(stereo) # 返回test.wav的左声道
③DelayAudio
声音延迟:由于从VOB里分离的AC3通常有延迟,所以用Azid转码得到的WAV也有延迟,在用AudioDub合并时就需要加上这个延迟。
例:WavSource("test.wav").DelayAuido(0.5) # 把test.wav延迟半秒
四、第三方滤镜
AviSynth最强大之处就是有数目繁多、功能强大的第三方滤镜;同时还可以调用VirtualDub以及AviUtl的滤镜;甚至还有特别开发的接口,可以让TMPGEnc和AviUtl读取AVS。
和内建滤镜不同,第三方滤镜需要先调用声明,再可以使用。
1、源文件滤镜
① MPEG2Dec
由dividee编写的读取DVD2AVI产生的d2v工程文件的滤镜,同时内建去除Noise的TemporalSmoother。
例:LoadPlugin("MPEG2Dec.dll")
MPEG2Source("test.d2v")
② MPEG2Dec2
trbarry在MPEG2Dec的基础上进行了改进,支持P4的SSE2指令集。用文本编辑工具打开d2v,把iDCT_Algorithm=?改成5就可以了。速度很快,效果也好,推荐P4 CPU的用户使用。
例:LoadPlugin("MPEG2Dec2.dll")
MPEG2Source("test.d2v")
③ MPEG2Dec3
在MPEG2Dec2的基础上再进行了改进,加入了Nic的图像后处理(PP),一定程度上可以减少Noise。好像除了P4的SSE2外,还加入了AMD的3D Now!优化,目前还在开发中,是个非常有前途的滤镜。
例:LoadPlugin("MPEG2Dec3.dll")
MPEG2Source("test.d2v",CPU=4) # CPU=4就是开启了PP模式
2、处理滤镜
① SimpleResize
放大缩小:由trbarry编写的,由于对SSE进行了优化,所以速度快,效果好。替代了AviSynth中的BilinearResize。和LanczosResize的米切尔双立方体算法不同,这个是单纯的双线性算法。LanczosResize的画质更锐利和真实,适合普通电影;而SimpleResize的画质较柔和,适合动画。
例:LoadPlugin("SimpleResize.dll")
SimpleResize(640,480)
② ColorYUY2
颜色补偿:Kiraru2002编写的滤镜。由于经过编码,得到的结果和DVD相比较,颜色有所改变,所以要对颜色进行补偿。
例:LoadPlugin("ColorYUY2.dll")
ColorYUY2(0,10,0,10,0,0,0,0,0)
3、交错滤镜
Decomb
IVTC和Deinterlace滤镜:由Donald A.Graft编写,新增加的专门处理NTSC格式动画的mode=2,要和Avisynth2.05以上版本使用,不然速度会慢一倍。
guide 0~2,默认0, NTSC用1,PAL用2,可以提高IVTC准确度。
gthresh 0~100,默认15,控制区分不同帧的程度。
post 默认true,用来处理IVTC遗漏的细节,使画面略微模糊。
threshold 0~255,默认15,控制post的程度。
dthreshold 0~255,默认9,控制threshold判定IVTC遗漏的程度。
blend默认true,在交错画面用渲染来替代填充。
chroma 默认false,在交错画面的亮度色度调整。
cycle 2~25,默认5,每n帧删除1帧,NTSC选5,PAL选25。
mode 0~2,默认2。
mode=0 对cycle里最相近的帧不进行处理。
mode=1 对cycle里最相近的帧进行处理,用于处理混合帧速。
mode=2 在一个很长的范围里进行帧对比,可以正确处理动画里由8帧或12帧复制为29.97帧的情况。
Threshold 默认0,控制mode=1时的处理重复帧的程度,Threshold默认100,控制mode=2时的处理重复帧的程度。
Quality0~3,默认2,采样和色度的质量,与速度成反比。
但是最近的几个版本似乎都存在一个问题,就是处理后的画面有波动现象,并伴随影片里文字闪烁现象,所以还是用老版本的保险。
例:LoadPlugin("Decomb.dll")
Telecide(Guide=1,Gthresh=50,Chroma=True,Quality=3,Post=false)
Decimate(cycle=5) # NTSC 3:2 PullDown
LoadPlugin("Decomb.dll")
Telecide(Guide=1,Gthresh=50,Chroma=True,Quality=3,Post=false)
Decimate(Cycle=5,Mode=2) # NTSC Progressive和Interlaced混合
LoadPlugin("Decomb.dll")
Telecide(Guide=2,Gthresh=50,Chroma=True,Quality=3,Post=false)
Decimate(Cycle=25) # PAL
4、字幕滤镜
① VobSub
Sub字幕:VobSub不但是外挂字幕的好手,内嵌字幕也是一样的强。
将字幕的2个文件test.idx和test.sub放在同一个目录下就可以了。
例:LoadPlugin("VobSub.dll")
VobSub("test")
② TextSub
SSA和ASS字幕:这个也是VobSub自带的,可以内嵌特效字幕。
例:LoadPlugin("TextSub.vdf")
TextSub("test.ssa")
今天终于弄明白了,为什么是“笨鸟先飞”而不是“傻鸟先飞”呢。
很简单,因为笨鸟根本就不傻。
笨鸟知道自己不如别人,所以只有用提前量来超越别人。
傻鸟自以为比别人强,结果错失击败对手的良机。
笨鸟只是反应慢而已,其实笨鸟的心里很清楚自己要干什么。
傻鸟可能反应很快,但是总是自以为是,眼高手低的错误时常发生。
笨鸟所历经的曲折,并不能算是失败,吃一堑,长一智,经验是最宝贵的。
傻鸟总想看着别人的成功,想着自己的成功,但是总也不去实践。
笨鸟虽然不是直线到达终点,却看到了更多的风景。
傻鸟总试图飞出直线,但是结果却恒是一个圆弧。
笨鸟因为先飞,所以总要先遇到一些问题。
傻鸟虽然没遇到过什么问题,但失去了处理问题的能力。
笨鸟总有资本向别人炫耀自己的成就。
傻鸟,没什么成就。
There is no failure but experience.
That is true.
快快乐乐的做一个笨鸟,先飞未必不好。
笨,并不是傻,只是处理事情比较慢而已。
傻,绝对不是笨,而是自以为是想当然。
ssa/ass无法加载自定义中文字体的问题很常见,几乎所有用过ssa/ass的人都遇到过。有些人通过更改DirectVobSub默认字体的方式暂时解决了该问题。但这毕竟不是根本的解决方法。
今天,终于搞明白为什么会无法加载自定义中文字体了。其实很简单,DirectVobSub按照指定的文字编码(Encoding)读入字幕并显示。而默认情况下,文字编码为0,即ANSI。在这个状态下,所有文字都会被认为是英文,从而调用Arial字体。而遇到中文按照Arial字体显示,则自动调用宋体。所以,要解决这个问题,只要把文字编码改回中文就行了。
打开字幕文件,在[V4 Style]区域中找到相应的样式,将最后一个值(即Encoding)从0(ANSI)改为134(GB2312)即可。再次在播放中调用字幕文件,问题已解决,自定义字体显示正常。
Trivial File Transfer Protocol (TFTP) is a simple protocol to transfer files. It has been implemented on top of the User Datagram Protocol (UDP) using port number 69. TFTP is designed to be small and easy to implement, therefore, lacks most of the features of a regular FTP. TFTP only reads and writes files (or mail) from/to a remote server. It cannot list directories, and currently has no provisions for user authentication.
In TFTP, any transfer begins with a request to read or write a file, which also serves to request a connection. If the server grants the request, the connection is opened and the file is sent in fixed length blocks of 512 bytes. Each data packet contains one block of data, and must be acknowledged by an acknowledgment packet before the next packet can be sent. A data packet of less than 512 bytes signals termination of a transfer. If a packet gets lost in the network, the intended recipient will timeout and may retransmit his last packet (which may be data or an acknowledgment), thus causing the sender of the lost packet to retransmit that lost packet. The sender has to keep just one packet on hand for retransmission, since the lock step acknowledgment guarantees that all older packets have been received. Notice that both machines involved in a transfer are considered senders and receivers. One sends data and receives acknowledgments, the other sends acknowledgments and receives data.
Three modes of transfer are currently supported by TFPT: netascii, that it is 8 bit ascii; octet (This replaces the "binary" mode of previous versions of this document.) raw 8 bit bytes; mail, netascii characters sent to a user rather than a file. Additional modes can be defined by pairs of cooperating hosts.
The current version of TFTP is version 2 (TFTPv2).
Protocol Structure - TFTP: Trivial File Transfer Protocol
The header structures of TFTP messages/packets:
RRQ/WRQ packet:
| 2 bytes | String | 1 byte | String | 1 byte |
| Opcode | Filename | 0 | Mode | 0 |
Opcode - Operation code or commands. The following are TFTP commands:
| Opcode | Command | Description |
| 1 | Read Request | Request to read a file. |
| 2 | Write Request | Request to write to a file. |
| 3 | File Data | Transfer of file data. |
| 4 | Data Acknowledge | Acknowledgement of file data. |
| 5 | Error | Error indication. |
Filename - The to be transferred file name.
Mode - Datamode. The format of the file data that the protocol is to transfer. It could be NetASCII Standard ASCII, Octet Eight-bit binary data, or Mail Standard ASCII.
Data packet:
| 2 bytes | 2 bytes | 0-512 bytes |
| Opcode | Block # | Data |
The Opcode is 3.
Block # - Block numbers on data packets begin with one and increase by one for each new block of data.
Data - Data field range from 0 to 512 bytes.
ACK packet:
| 2 bytes | 2 bytes |
| Opcode | Block # |
The Opcode is 4.
Block# - Block number echoes the block number of the DATA packet being acknowledged.
A WRQ is acknowledged with an ACK packet having a block number of zero.
Error Packet:
| 2 bytes | 2 bytes | String | 1 byte |
| Opcode | Error | ErrMsg | 0 |
The Opcode is 5.
Error code - an integer indicating the nature of the error.
0 Not defined, see error message (if any).
1 File not found.
2 Access violation.
3 Disk full or allocation exceeded.
4 Illegal TFTP operation.
5 Unknown transfer ID.
6 File already exists.
7 No such user.
ErrMSG - Error message is intended for human consumption, and should be in netascii. It is terminated with a zero byte.
世界杯开赛前,下到了这首所谓的“德国世界杯第二主题曲”《Deutschland》。当时还被其动感的节奏所迷惑。但是找到了歌词可就不一样了,感觉实实在在的被骗了,不懂德文的下场。歌词如下(附修正版中文歌词):
Deutsch, deutsch, deutsch, deutsch, deutsch, deutsch
Germany, Germany, Germany, Germany, Germany, Germany
德意志,德意志,德意志,德意志,德意志,德意志
Natürlich hat ein Deutscher "Wetten, dass … ?" erfunden
Of course, German invented "Wetten, dass … ?"
德国人发明了“Wetten, dass…?”这个节目
Vielen Dank für die schoenen Stunden
Thank you for the beautiful time
非常感谢,我们过的非常愉快!
Wir sind die freundlichsten Kunden auf dieser Welt
We are the friendliest customers around the world
我们是这个世界上最友善的顾客
Wir sind bescheiden, wir haben Geld
We are modest, we have money
我们谦虚并富有
Die Allerbesten in jedem Sport
The very best ones in each sport
我们在每项运动中都有最好的运动员
Die Steuern hier sind Weltrekord
The taxes are the world record here
德国的捐税世界闻名
Bereisen Sie Deutschland und bleiben Sie hier
Visiting to Germany and staying here
欢迎来德国旅行和逗留
Auf diese Art von Besuchern warten wir
We wait for this kind of visitors
我们期待您的光临
Es kann jeder hier wohnen, dem es gefaellt
Everyone can live here, which his pleases
只要高兴,谁都可以来德国居住
Wir sind das freundlichste Volk auf dieser Welt
We are the friendliest people around the world
我们是世界上最友善的人
Deutsch, deutsch, deutsch, deutsch
Germany, Germany, Germany, Germany
德意志,德意志,德意志,德意志
Nur eine Kleinigkeit ist hier verkehrt
Only one little thing is wrong here
要澄清的一点小误会是
Und zwar, dass Schumacher keinen Mercedes faehrt
That is, Schumacher doesn’t drive Mercedes
舒马赫开的并不是梅塞德斯车(奔驰车)
Das alles ist Deutschland
This is Germany
这就是德国
Das alles sind wir
This is what we are
我们就是德国人
Das gibt es nirgendwo anders
This is not different from anywhere else
这里和其他地方一样
Nur hier, nur hier
Only here, only here
就是这里,就是这里Das alles ist Deutschland
This is Germany
这就是德国
Das alles sind wir
This is what we are
我们就是德国人
Wir leben und wir sterben hier
We live and we die here
我们在生在这里,死也在这里
Deutsch, deutsch, deutsch, deutsch
Germany, Germany, Germany, Germany
德意志,德意志,德意志,德意志
Deutsch, deutsch, deutsch, deutsch
Germany, Germany, Germany, Germany
德意志,德意志,德意志,德意志
Es bilden sich viele was auf Deutschland ein
There are many images on Germany
很多人都对德国抱有不实的偏见
Und mancher findet es geil, ein Arschloch zu sein
And someone finds cool to be assholes
而有的人则觉得做一个混蛋是一件很爽的事情
Es gibt Manchen, der sich gern über Kanacken beschwert
There is someone, who aggrieves about foreigners
有些人喜欢抱怨外籍劳工 [尤指土耳其人]
Und zum Ficken jedes Jahr nach Thailand faehrt
And go to Thailand to fuck each year
而自己却每年都去泰国逍遥
Wir lieben unsere Autos mehr als unsere Frauen
We love our cars more than our wives
我们爱老婆但更爱汽车
Den deutschen Autos koennen wir vertrauen
We can trust the German cars
德国车值得信赖
Gott hat die Erde nur einmal geküsst
God kissed the earth only once
上帝只亲吻过地球一次
Genau an dieser Stelle, wo jetzt Deutschland ist
Exactly here, where Germany is now
那个地方就是现在的德国
Wir sind überall die Besten natürlich auch im Bett
We are the best ones everywhere, of course, also in bed
我们什么都要做到最好,床上功夫也是一样
Und zu Hunden und Katzen besonders nett
And especially nice to dogs and cats
而且我们喜欢猫和狗
Das alles ist Deutschland
This is Germany
这就是德国
Das alles sind wir
This is what we are
我们就是德国人
Das gibt es nirgendwo anders
This is not different from anywhere else
这里和其他地方一样
Nur hier, nur hier (zwo, drei, vier)
Only here, only here (two, three, four)
就是这里,就是这里(二、三、四)Das alles ist Deutschland
This is Germany
这就是德国
Das alles sind wir
This is what we are
我们就是德国人
Wir leben und wir sterben hier
We live and we die here
我们在生在这里,死也在这里
Wir sind besonders gut in und auf die
Fressehauen We are especially good in and on the eat-strike
我们是出色的战士
Auch im Feuerregen kann man uns vertrauen
We can be trusted also in the fire rain
即使在枪林弹雨中人们也能信任我们
Wir stehen auf Ordnung und Sauberkeit
We stand on order and cleanliness
我们讲究秩序和整洁
Wir sind jederzeit für’n Krieg bereit
We are always ready for the war
我们枕戈待旦
Schon Gross an die Welt zieht es endlich ein
The large world is drafted into one finally
总有一天世界会统一
Wir koennen stolz auf Deutschland sein
We can be proud on Germany
我们能为德国而骄傲
Schwein, Schwein, Schwein, Schwein
Swine, Swine, Swine, Swine
下流痞,下流痞,下流痞,下流痞
Schwein, Schwein, Schwein, Schwein
Swine, Swine, Swine, Swine
下流痞,下流痞,下流痞,下流痞
Das alles ist Deutschland
This is Germany
这就是德国
Das alles sind wir
This is what we are
我们就是德国人
Das gibt es nirgendwo anders
This is not different from anywhere else
这里和其他地方一样
Nur hier, nur hier
Only here, only here
就是这里,就是这里
Das alles ist Deutschland
This is Germany
这就是德国
Das alles sind wir
This is what we are
我们就是德国人
Wir leben und wir sterben hier
We live and we die here
我们在生在这里,死也在这里
Das alles ist Deutschland
This is Germany
这就是德国
Das alles sind wir
This is what we are
我们就是德国人
Das gibt es nirgendwo anders
This is not different from anywhere else
这里和其他地方一样
Nur hier, nur hier (zwo, drei, vier)
Only here, only here (two, three, four)
就是这里,就是这里(二、三、四)
Das alles ist Deutschland
This is Germany
这就是德国
Das alles sind wir
This is what we are
我们就是德国人
Wir leben und wir sterben hier
We live and we die here
我们在生在这里,死也在这里
计划总是美好的。
去年6月,计划着转学拿COOP,今年暑假工作。
结果,由于转学分太多,COOP差点被拿下,在好说歹说之后,学校同意于明年一月份开始。
于是,更改计划,今年暑假打工,争取找一个当地公司。
结果,由于种种原因(懒、国际学生、暑假、当地学生等等),泡汤。
愤而,再次更改计划,给教授做义工。
结果,发出去若干封信都石沉大海。
最后,破罐子破摔,在家呆着吧。
结果,不知道为什么时间过得这么快,都到现在了,还在闲着。
世界杯开始了,总算有个消遣了。
结果,好像没看过几场直播。
没事闲着,无语了。
